Transitioning to Quantum-Safe Cryptography: Exploring the Role and Value for Developing and Implementing a Cryptographic Bill of Materials
September 12, 2024First Authors
Ben Rodes (Microsoft), Rodney Moseley (Microsoft), Raul Garcia (Microsoft), Nicklas Kortge (IBM Research), Michael Osborne (IBM Research), John Buselli (IBM Research), Jayati Dev (Comcast), Gero Dittmann (IBM Research)
Contributors
Lory Thorpe (IBM Research), Reza Azarderakhsh (PQSecure), Basil Hess (IBM Research), Carmichael Patton (Microsoft), Andrei Popov (Microsoft), Vaibhav Garg (Comcast), Elie Alhajjar (RAND), Scott Simon (MITRE)
Abstract
The emergence of quantum computing poses new and significant threats to current cryptographic systems used across industries. Transitioning to a quantum-safe era poses significant challenges and requires comprehensive planning and action. Developing a Cryptographic Bill of Materials (CBOM) is vital in understanding, managing, and effectively communicating cryptographic dependencies. CBOMs will aid in addressing post-quantum migration and provide a strategic advantage in assessing cryptography in a rapidly evolving threat landscape. We explore the concepts and challenges of CBOMs. Our goal is to promote the development of cryptography inventories that can effectively assess cryptographic needs in dynamic and complex systems.
1 – Introduction & Motivation
Cryptography is a foundational technology of security-critical systems and organizations; however, the correct and secure application of cryptographic algorithms is prone to error due to its inherent complexity, nuances of their configurations and cryptographic APIs, lack of domain knowledge by practitioners, etc. Moreover, assessing an organization or application’s cryptographic posture or targeting where upgrades are required is complex. The application of cryptography is often dispersed across various systems, opaque and hardcoded. Even when cryptography is applied correctly, secure software systems exist in an ever-evolving, adversarial ecosystem. New technological advances or weaknesses may immediately render previously accepted cryptographic approaches obsolete and insecure.
One impending and highly publicized risk to cryptography today is the recent accelerated advancements to quantum computers. Once a powerful quantum computer of sufficient capability is developed, referred to as a Cryptographically Relevant Quantum Computer (CRQC), many existing cryptographic approaches will be weakened or broken. National governments and industry standards organizations are issuing guidance that includes the requirement to inventory cryptography as a prerequisite to migrating to new post-quantum algorithms.
While the quantum risks have garnered more attention and initiated new regulatory mandates, a cryptographic inventory is a fundamental prerequisite for other critical cybersecurity capabilities. These capabilities include proactively assessing and strengthening cybersecurity defenses, responding quickly to evolving threats and attesting that the cryptography being used is what is expected and compliant with policy. Any future or existing threats to cryptography (including quantum threats) would require the same core capabilities. The foundational step for these capabilities is conducting and maintaining a thorough cryptography inventory and assessment. This process identifies where cryptography is in use, assesses how vulnerable and critical it is to the business, and pinpoints the location of weaknesses when vulnerabilities are found. An inventory is a basis for monitoring, planning and effecting a transition to secure alternatives (e.g., quantum-safe algorithms). It is especially crucial for entities safeguarding data requiring prolonged (e.g., multi-decade) protection.
This whitepaper provides an overview of the concepts of a cryptography inventory, which is a complete list of cryptographic entities in a system or organization. A systematic representation of such an inventory is commonly referred to as a Cryptographic Bill of Materials (CBOM). We discuss what a CBOM is, its purpose, how it might be applied and where, and the challenges and considerations that must be undertaken in its development. The target audience is any individual or organization seeking to understand and explore the problem of creating an inventory, inventory tools, or standards of cryptography inventories. The goal is to initiate a dialogue towards developing maturity in cryptography inventory capabilities and practice and to enable an efficient long-term solution to discover and manage system cryptography.
2 – What is a Cryptography Inventory?
Abstractly, a cryptography inventory (also commonly referred to as a cryptographic or cryptography bill of materials – CBOM) can be considered a map or summary of all the cryptography deployed in an organization. The inventory describes what cryptography is used by which applications, for what purpose, and in which configuration, along with sufficient information to locate specific uses and configuration data in an organization’s deployed infrastructure.
A cryptography inventory is not a mere bureaucratic artifact. It is a vital tool that serves as the first step in assessing a software system’s compliance with standards, best practices, and known vulnerabilities. By maintaining an up-to-date list of cryptographic elements, the inventory provides the necessary information for conducting any required or desired security assessments.
2.1 – Inventory Graphs: A Conceptual Model
A CBOM describes cryptographic entities (see Section 2.3) and their dependencies and configurations. These entities can include certificates, keys, algorithms, and secure protocols. Entities are mapped to systems and applications, their uses, and their configurations, and can have additional properties such as quantum security levels.
Since cryptographic entities do not exist in isolation for a given system, and may have complex interdependencies and configurations, we propose a conceptual model for CBOMs as an Inventory Graph. As a conceptual model, we do not prescribe a CBOM necessarily be developed as a graph in practice. Rather, we propose that any CBOM implementation would need to consider the concepts and challenges as described in an inventory graph model.
The exact form an inventory takes is the subject of current standardization efforts, but we propose that the basis of a cryptographic inventory is a property graph of nodes and edges:
- Inventory Nodes: represent any ‘entity’ of cryptography, including algorithms, operations, and configurations. Nodes may have arbitrary properties about the entity and arbitrary relationships (edges) to other nodes.
- Inventory Edges: relate inventory nodes to each other, for example, by associating algorithms to their operations, configurations to their algorithms, multiple algorithms to a composite operation or protocol, etc.
We can assess the application of cryptography by navigating from entities of interest (e.g., navigating all nodes of a class of algorithms) and isolating a subgraph of all relevant entities and relationships for any given system or subsystem.
The inventory graph can be imagined as a cryptography-specific system property graph[1], a graph that captures arbitrary properties and relationships at various levels of abstraction. The essential characteristic of the graph is that nodes and edges are not homogenous. Nodes and edges can represent entirely disparate constructs. Graph slices (sub-graphs) compose those nodes and edges around larger concepts (e.g., cryptographic protocols combining multiple algorithms and systems applying many different protocols). The graph combines these associations to allow for ease of assessment and review. The benefit is that assessments can quickly adapt to new needs by altering the traversal and slicing of the graph. Furthermore, the graph offers flexibility to account for new threats over time (by adding new nodes and edges, and updating existing graph properties), motivating new additions to the inventory.
The nodes and edges modeled and associated in the graph are chosen based on whether they might be compromised by known or newly discovered weaknesses or are regulated by standards or organization-specific practices. What is ultimately represented in a CBOM is based ultimately on what downstream analyses are applied or expected to be applied to validate that the use of crypto is acceptable. The inventory needs to be sufficient to facilitate these downstream assessments (Section 5.5).
For example, if the only focus of an inventory is on quantum computing threats, then the inventory would focus on identifying applications of asymmetric cryptography that are broken by quantum computing and uses of block ciphers that are weakened by quantum computing (broken or weakened by Shor’s or Grover’s algorithm [1] [2]). As hybrid asymmetric cryptography is proposed to bridge the gap between quantum-safe cryptography and existing algorithms, the graph may need to associate these old and new algorithms in concert further.
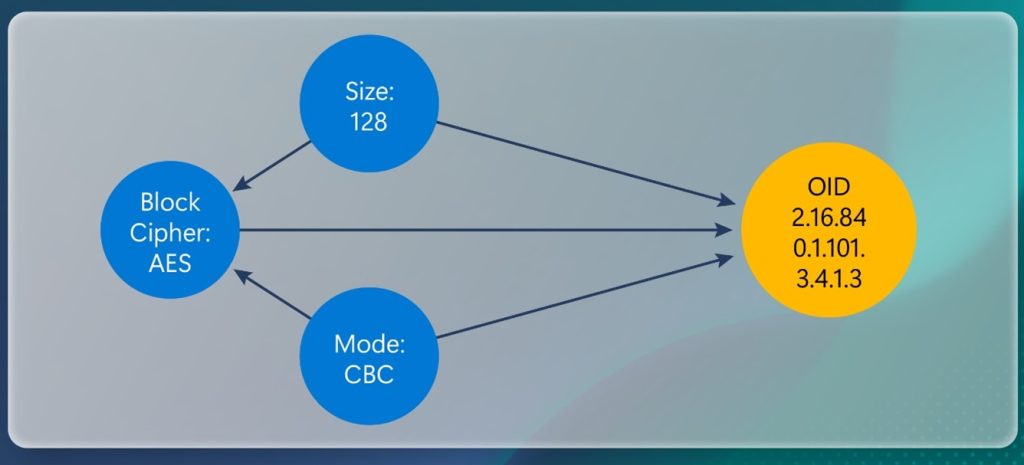
Figure 1. Sample Inventory Graph Subgraph
Figure 1 illustrates a very high-level concept of how the graph might show interdependencies for a specific cryptographic property, AES-128-CBC. In this example the nodes represent Block Cipher: AES, Key Size: 128, Block Mode: CBC, and a global OID reference (OID 2.16.84.0.1.101.3.4.1.3) providing a normalized category for the complete concept: AES-128-CBC [3]. The nodes and edges are simplified for the example but in practice would have nested properties, e.g., edge descriptions and locations for the key size, block mode, and cipher usage (discussed in Section 2.2).
The OID node represents a higher-level categorization/organization of the larger concept applied in the system, which might be desirable for users if they need to have consistent and formalized ‘handles’ to core cryptographic abstractions. Edges connecting the cipher, size and mode therefore indicate configuration in this example whereas the edges connecting the OID node indicate the components that make of AES-128-CBC as found in the system.
2.2 – Property vs. Edge Ambiguity
As presented, nodes may have arbitrary properties about the entity they represent. This raises the question of what a property is and what is an edge. In many cases, the distinction of separate nodes might be considered obvious (e.g., the entity’s location in the system), yet in other cases, it may be obscure or debatable.
Again, consider Figure 1, where a system may apply AES-128. Several options exist for how this might be modeled in an inventory:
- A single node representing AES-128 as a complete concept
- A node representing the algorithm AES with a property of ‘key size’ set to 128 bits
- A node representing the algorithm AES, a node presenting 128 bits, and a relationship’ key size’ connecting the two
Further properties and configurations (i.e., the block mode) compounds these considerations.
Often, how the inventory should model such cases will be favorably viewed one way or the other depending on how the underlying system or cryptographic APIs apply the algorithm (e.g., as a sequence of configuration separate steps followed by an application of the algorithm, or as a single invocation doing both at once). An attempt to separate entities may be pedantic and noisy in some cases and fundamental in others. How the entities are modeled and connected may ultimately depend on if there are different locations to attribute to the configuration and use of each aspect of cryptography.
To further illustrate this potential for ambiguity, consider Figure 2. The first line is an instantiation of an AES cipher algorithm in the OpenSSL API for C/C++ [4], and the second line is an instantiation of an AES cipher algorithm in Python’s pyca/cryptography API [5].

Figure 2. Instantiation of AES cipher algorithm in OpenSSL in C++ and pyca/cryptography in Python
OpenSSL’s approach makes it more evident and favorable to inventory “AES-128-CBC” as a single all-inclusive node. The inventory may choose to identify the entire string configuration as the node in this case. Key size and block mode properties can still be explicitly specified, but the location of the entity configuring that size is the same as the entity determining the algorithm.
The Python approach (second line) raises new challenges. In particular, the key used in the initialization may have come from multiple sources, and the sizes of those keys need to be evaluated to establish the size. This alludes to the need to identify every size configuration for all keys that may make it to AES initialization, and document them discretely in the CBOM. Each size may be in a different location in code, suggesting an approach where the sizes are separate nodes with varying location properties and associated with the algorithm AES through a ‘key size’ edge.
Examples like these show that separating entities into separate nodes may depend on whether the entity is located separately from another distinct entity. Separate location implies separate nodes, but nodes presenting these entities may not always be in separate locations.
Ultimately, all these considerations are up to interpretation, but as more complex and nuanced systems are combined into a single inventory, interpretations may clash. A more general approach might be taken, even if considered pedantic in some instances, to allow more flexibility in the future. Whatever approach is taken should be dictated by what is most easily generated, assessed and evolved. Downstream assessments must be resilient to (i.e., be able to ingest) the chosen classification scheme.
2.3 – Terminology Confusion and Debate
Even between practitioners in the field, the terminology of what should be contained in an inventory can be inconsistent. Cryptographic assets, metadata, properties, entities, artifacts, operations, etc., are examples of terminology that is often used. We have chosen to consolidate all of these into the concept of a node in the graph representing an ‘entity.’ We do not intend to settle the terminology debate, propose a unifying taxonomy, or explicitly dictate what an inventory must specify, but rather to keep the concepts abstract enough to focus on the core underlying considerations and challenges of cryptography inventories.
The inventory graph concept, as envisioned as a system property graph, is meant to capture disparate concepts. As such, nodes and edges can represent any arbitrary concept in cryptography. Of most importance is that downstream assessments know how to assess the graph. This interdependency between the inventory and assessments ultimately needs to drive standardization of the constructs modeled as nodes and edges.
2.4 – Example Inventory Contents
The following represent example (non-prescriptive) cryptographic entities/relationships that may appear in an inventory:
- Component or application being evaluated.
- Function or feature using cryptography.
- Symmetric algorithms, function, key size, operations
- Asymmetric algorithms, function, key size, operations
- Hash algorithms, digest size
- Crypto algorithm implementation (hardware, software)
- Crypto provider (HSM, library)
- Crypto vendor (Vendor or open source)
- Interoperability with business/crypto partners
- Secret (e.g., Key) provisioning and storage
- Date Stamp
2.5 – SBOM vs. CBOM
Transparency in software composition is essential to properly assess the presence of vulnerabilities within the code and determine supply chain and operational risks. The transparency required to address and avoid such issues effectively starts with a Software Bill of Materials (SBOM). In their most basic form, SBOMs list the open-source, commercial, and, ideally, proprietary components utilized in creating a piece of software. SBOM mechanisms typically catalog component versions, patch status, and licenses. Any organization purchasing third-party software can readily benefit from asking their vendor for an SBOM. Although SBOMs have been under development for nearly a decade, they first came to broad attention due to the U.S. Presidential Executive Order 14028 [6].
As discussed so far, cryptography is typically buried deep within components used to compose and build systems and applications. In addition, modern companies utilize various vendor technologies whose components often need to be more readily discoverable. That means understanding where cryptography is deployed across a system’s dependent components and how it is implemented in each element. CBOMs, which are very similar to SBOMs, offer this clarity. A CBOM describes cryptographic entities and their dependencies within a software component, providing a comprehensive view that enhances security and reassures you of the safety of your software.
A CBOM is very similar to an SBOM. Moreover, like an SBOM, a CBOM can be integrated into the device development lifecycle to identify third-party components that contain vulnerabilities. A CBOM can also be cross-referenced against NIST’s NVD to automate vulnerability monitoring and alerting. The CBOM, however, also includes a list of hardware components, so it aims to minimize supply chain attacks from both software and hardware fronts.
Moreover, like an SBOM, a CBOM can also be integrated into a development lifecycle to identify third-party components that contain vulnerabilities. A CBOM can also be cross-referenced against the NIST’s National Vulnerability Database (NVD) [7] to automate vulnerability monitoring and alerting. CBOMs add cryptographic artifacts and extend the SBOM concept. Combined, they can be embedded with each application, providing compliance auditors with more reliable audit results. CBOM standards, such as those now included in the CycloneDX 1.6 standard [8], can be used to help understand and govern the software supply chain, ensuring the highest level of reliability and efficiency.
Cryptographic governance is not just necessary, but a strategic advantage in the current software landscape. It requires understanding where cryptography is located, its use, and the methods needed to monitor changes. In addition, much of the cryptography that organizations use is in third-party components and applications, making it essential to include these elements in the governance scope. CBOMs extend the SBOM concept and enable software buyers to know more about their purchasing activities. They also help buyers prioritize their security needs based on risk-oriented criteria, giving them a strategic edge in software procurement and compliance.
3 – What’s the Purpose of a Cryptography Inventory?
Assessment of the quality of any system or organization’s cryptography first requires identifying what cryptography is actively used. The fundamental purpose and benefit of a cryptography inventory is to assess the system with respect to the acceptability of the applied cryptography by enumerating all aspects subject to evaluation. Acceptability is a broad and evolving concept that differs between organizations and fields and includes factors such as policy compliance. A reliable inventory is a critical component in initiating and monitoring any changes on an ongoing basis.
Assessments should consider whether applied cryptography has known vulnerabilities, but generally, organizations and regulations may impose specific restrictions regardless of known vulnerabilities. An inventory for quantum computing threats would focus on applications of cryptography weakened or broken by Grover’s or Shor’s algorithms [2] [1].
While the general purpose of an inventory is to provide the basis for evaluating any organization’s cryptographic security posture generally, the current quantum threats have largely motivated the push for inventories recently. In this section, we further motivate the purpose of inventories with respect to current quantum-based policy initiatives and the potential implications of policies on organizations to comply with these initiatives.
3.1 – Current Public Policy Initiatives
Cryptography inventories specifically address the pressing quantum initiatives currently underway in many organizations and agencies. The following example initiatives are driven by United States agencies; however, different geographies around the world will have their inventorying processes influenced by their own regulations and policy-making processes.
The current initiatives were triggered by the White House’s Executive Order to improve the United States’ cybersecurity [6] and National Security Memorandum 10 to mitigate risks to vulnerable cryptographic systems [9]. Additionally, directives for agencies on the Migration to Post-Quantum Cryptography [10] state that agencies must enhance the security of their software supply chains and establish a prioritized inventory of deployed cryptographic systems.
These federal directives have also led US governmental agencies to start additional initiatives in this area, including those addressing critical infrastructure. The Department of Homeland Security released a post-quantum migration roadmap that outlines the need for a detailed cryptographic inventory [11]. NIST recently released their draft inventorying guide, Migration to Post-Quantum Cryptography Quantum Readiness: Cryptographic Discovery, outlining what to inventory, including CBOMs [12]. Apart from these initiatives, there is ongoing work on post-quantum migration, with a focus on specific sectors, like the work being done in telecommunications by the GSMA [13].
3.2 – Implications for Organizations
New standards and directives for cryptography inventories would mean that organizations must soon begin the inventorying process. Establishing a comprehensive inventory demands a meticulous approach and a robust governance structure, necessitating the active involvement of senior executives and the direction of resources toward meeting the long-term objectives of inventorying. All these tasks come with their challenges and constraints that depend on the organization’s size. Ideally, there should be:
- A streamlined inventory process, including manual and automated CBOM generation across different networks, applications, and infrastructure.
- An operational inventory process that integrates into the existing DevSecOps pipelines that would trigger updates in response to new or updated assets or threats.
- A robust inventory that highlights any dependencies on cryptographic supply chains and a plan to manage requirements based on those dependencies without causing system downtime.
A dedicated governance team oversees the entire process, ensuring alignment with organizational goals and compliance with any upcoming inventorying policy. Designating cryptographic champions within the organization helps socialize the impact of risk and drives the implementation of security plans.
4 – Targets and Scope: What, Where, & When Inventory?
4.1 – Inventory Targets
Creating an inventory involves identifying the various components of a system that require attention regarding cryptography, including third-party tools, applications, source code, network traffic, and hardware. Each component has different requirements and necessitates distinct inventory methods or tools. The ultimate objective is to build a comprehensive, unified inventory model capable of discovering both known and unknown uses of cryptography within the system’s boundaries.
Developing an inventory first requires understanding the exact aspects of the system the inventory should focus on and at what level of granularity. This determines what kinds of data need to be examined to create an inventory (what systems or artifacts contain uses and configurations of cryptography).
Example inventory targets include:
- Third-Party Tools/Applications: Tools and applications used by the system have their configurations and settings for cryptography and where source code might not be available. Consider, for example, how a database is configured and applied to protect data.
- Application Source Code: Applications of cryptography within the available source code of the application.
- Data at Rest: Cryptography configurations ingested into the system components, e.g., configuration files and certificates.
- Data Over Networks: Cryptography used to protect data in transit across networks. This can involve evaluating secure communication ports and protocols such as TLS/SSL, VPN configurations, and secure API interactions.
- Hardware: Cryptographic hardware components such as Trusted Platform Modules (TPM), Hardware Security Modules (HSM), and Internet of Things (IoT) devices.
Different targets necessitate unique inventory mechanisms or tools, each with its limitations in capabilities and scope. For example, details about algorithms and their configurations stored in configuration files may not be accessible to inventory tools, only assessing the source code where configuration files are ingested. Therefore, the inventory of any specific system target must explicitly account for the discovery of unknowns (see Section 5.3) in addition to known uses of cryptography. Integrating data from multiple inventory sources into a unified, federated inventory presents both a challenge and a goal for developing a mature inventory model (see Section 5.4).
4.2 – Inventory Life Cycle
Developing an inventory also requires addressing at what point an inventory should be generated in the development and deployment of a system. Inventories may need to be considered at each stage of the development process, including post-deployment stages. Software development proceeds through stages of composition, each with its analyses: static application security testing (SAST) for the source code, software composition analysis (SCA) for library dependencies, and image scanning for containers.
Each stage may need to develop its own inventory. Cryptographic entities are added from previous stages, and the results are passed to the next stage, collecting all partial inventories along the way. The inventories may be combined for a holistic view, but there is also value in keeping the link between an entity and the stage at which it was introduced to understand where a weakness has been introduced and to guide remediation. For example, post-deployment inventories may be generated and assessed dynamically. This involves assessing network traffic and intercepting cryptography API usage live. These dynamic inventories require additional overhead and should be limited to uncertainties in the inventory that cannot be evaluated pre-deployment or statically.
4.3 – Stakeholder-Driven Granularity of Inventory Scope
The scope of an inventory will depend on the stakeholders involved. Software development and IT operations are sufficiently different environments, typically with various stakeholders and responsibilities, to maintain separate inventories. Figure 3 illustrates the scope and dependency of assets in the purview of both operational and development scopes.
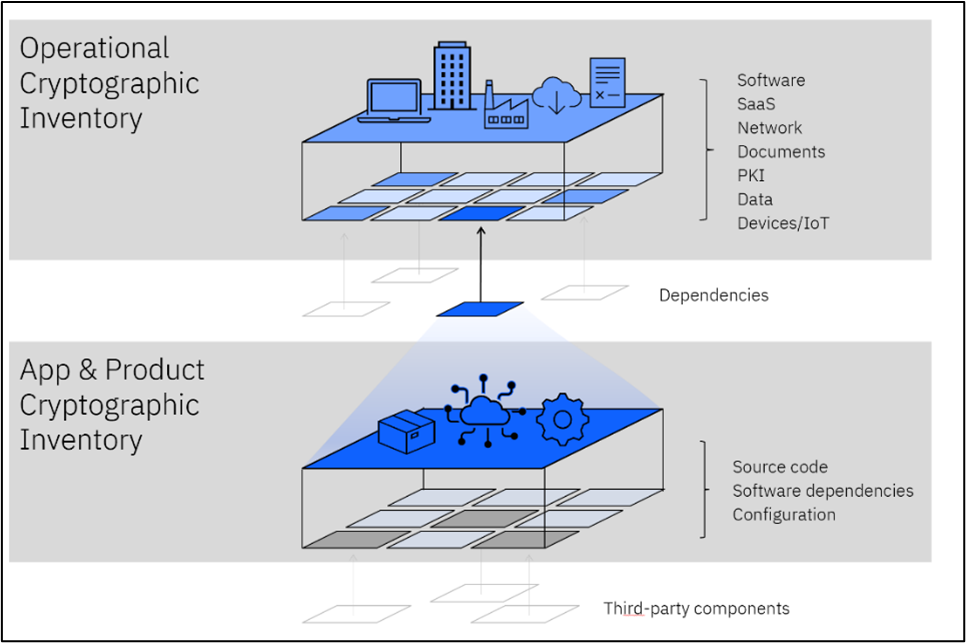
Figure 3. Inventory scopes: development, operations.
A product development team will be required to generate an inventory that covers all the cryptography in the applications that they build. This inventory can be used to automatically evaluate cryptographic policy during the development phase (e.g., Shift Left compliance). See for example the OWASP Dependency Track for dependency management [15].
An operations team will require a cryptography inventory that covers all dimensions of the larger system, including the context in which applications are deployed. Scanning all operational components may not be possible, meaning that an inventory may need to be assembled from both internal and external third parties.
5 – Additional Inventory Challenges and Considerations
Many challenges and considerations to the development and application of CBOMs have already been presented; however, in this section, we provide a further discussion on several key concerns.
5.1 – Capability vs. Usage
There are two general approaches to addressing identification of cryptography in software systems:
- Capability-Driven Identification: What cryptography exists in my system?
- Usage-Driven Identification: What cryptography is used in my system?
Inventories can be generated with either goal in mind. The distinction is that a capability-driven approach does not take into consideration if found entities are ever applied, whereas a usage-driven approach does take this into consideration.
As an example, consider an inventory performed on a cryptography API. Given that such an API should support all cryptography, we may see that every possible algorithm could be used in every possible configuration, but as an API, we are unable to see any specific use. To see its use, we would have to look at the API used within a more extensive system and determine what parts of the API are applied.
Another example is static analysis from source code, which can reveal a TLS stack that can use TLS 1.0 -> 1.3. Further scanning of the configuration may reveal more precise information, such as the TLS stack is only configured to use TLS 1.2 & TLS 1.3, but that configuration is independent of the code. The actual usage of the actual protocol and suites could further be detected by network monitoring tools.
A capability-driven approach to an inventory benefits organizations, as some standards or practices may require removing even the capability of weak or generally unapproved cryptography. Furthermore, a capability-driven inventory is easier to produce as a first step. Starting with a capability-driven inventory provides a phased effort to develop more sophisticated cryptographic inventories incrementally. A capability inventory can be viewed as providing a complete attack surface, whereas the usage inventory provides more specificity.
The distinction between these approaches speaks to some degree about the maturity level of the inventory. Inventories should consider documenting their approach (capability or usage), but inventories may need to identify their general maturity level to provide context for further review and acceptance (see Section 5.4).
Inventories may also apply a combination of both capability and usage driven analyses, for example, to address unknowns (Section 5.3). If a static analysis generating CBOMs is unable to determine whether a specific algorithm is used, the inventory can be supplemented with a dynamic analysis to determine uses at run time. As usages are detected, the inventory is updated to document the current known algorithms used with the caveat that the set may not be complete.
5.2 – Locating Entities
Two nuanced challenges in creating an inventory are what to identify precisely and what location to tag as part of the inventory. It is not sufficient to say a system uses some algorithm with some configuration without specific location information. Cryptographic algorithms, operations, configurations, etc., must be identified in the system precisely (e.g., a line in the source code) to allow for further assessment and, if needed, alteration. This issue raises the question of what component of the system represents an entity in the inventory. This question may have a variety of answers.
Consider source code, where an algorithm can be instantiated in a separate line of code from where the algorithm is eventually applied. Figure 4 is taken from the Python cryptography module docs and illustrates this challenge. Note chosen_hash is an instantiation of SHA256, but that algorithm is not applied until the call to hasher.update. The result of that operation isn’t used until private_key.sign.
Where do we identify the use of SHA256? At the instantiation (hashes.SHA256()) or at the operation of the digest operation (hasher.update), or at the signing operation (private_key.sign)? In this instance, we ask if instantiation is the cryptographic entity, or is the entity in the applications of the algorithm (the operations).
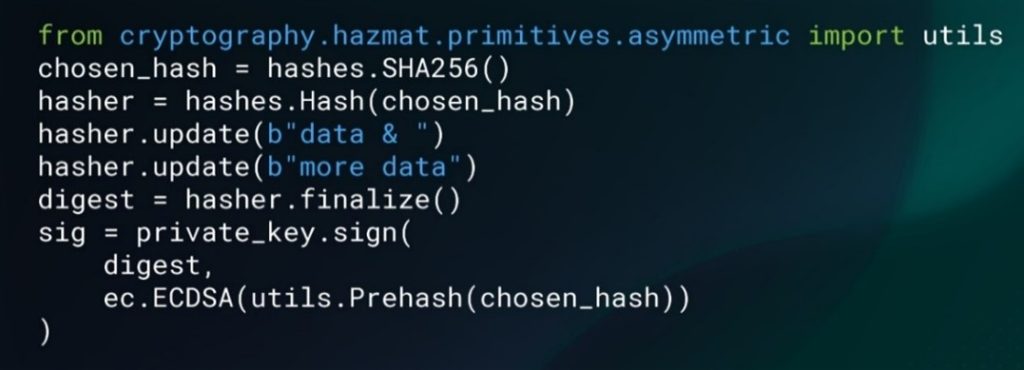
Figure 4. Algorithm instantiated is separate line of code than when it is applied
The ultimate answer may involve a combination of both viewpoints so long as downstream analyses and reviewers have sufficient information to complete validation and easily effect change if the assessments show some aspect of cryptography is unacceptable. Addressing unknowns (Section 5.3) may also require that both approaches are taken.
5.3 – Known Unknowns
When generating a cryptography inventory, it is easy to fixate on what we see clearly in the target systems and components of those systems we are evaluating. It takes special consideration to look for things that are missing but where we can detect their absence.
Consider the example in Figure 4 where a hash is specified, and its application is obvious (hashes.SHA256()). What if the hash came from a file or other source that is not in the source code or in any aspect of the system for which we currently generate an inventory? See Figure 5, where a digest name is provided by a variable (lpzDigestName) provided by a user. We see that some hash algorithms are used, but not the specific hash algorithms (what is stored in the variable). This would indicate a “known unknown“, a location where we know a specific cryptographic algorithm or configuration is specified, but the details (e.g., which algorithm exactly) are unknown.
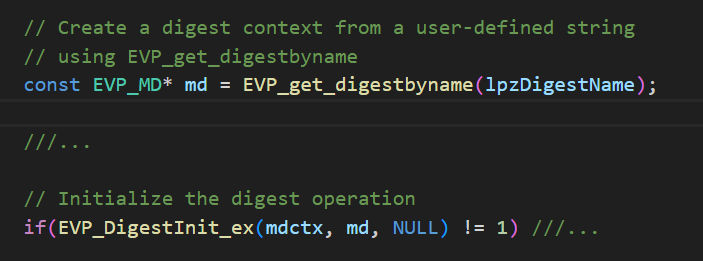
Figure 5. Digest name defined outside the code
A cryptography inventory must take into consideration not only the known and obvious uses of cryptography, but also the known unknowns. These areas are a risk and identify inventory gaps that will require further assessment. This may mean the inventory analyses are improved or supplemented with additional inventory tools to fill in these gaps, or human reviewers must manually assess the actual configuration.
5.4 – Inventory Maturity Model
The overall quality of an inventory must be established to address inherent doubt about how much the inventory can be trusted or relied upon as the basis for any cryptographic assessment or regulatory compliance. Every challenge, complexity, and nuance in inventory generation is another variable impacting what an inventory provides and with what level of precision. If these variables are not explicitly acknowledged and presented with the inventory, there is no way to ensure the results are meaningful, complete, or accurate. The inventory would be prone to manipulation and bias, allowing organizations to sway system assessments, for example, to avoid necessary system changes that may be costly.
A cryptography inventory maturity model or metric is needed to standardize the variables impacting inventory quality to either (1) categorize discrete maturity levels or (2) measure maturity on a continuous spectrum. Intuitively, a metric for various uncertainty variables would give a more informed understanding of an inventory’s maturity since an inventory may be inadequate in one dimension but highly mature in another. For example, an inventory may be limited to only examining C/C++ source code for OpenSSL usages, but that inventory may be mature in finding actual cryptography usage (as opposed to capabilities independent of use, Section 5.1) and unknown algorithm configurations (Section 5.3), not only interprocedurally but across library bounds (i.e., usages occurring through nested library imports).
A maturity model should not suggest that lower maturity inventories have no or little value. Lower-maturity inventories have value, especially when building and adopting inventory technologies. A lower maturity indicates where further efforts are necessary for more precise inventory improvements. Additionally, inventory assessment can be weighted by the inventory maturity level to allow for flexibility as the level improves. Lower maturity inventories may even be acceptable generally, without further improvement, if the identified areas of diminished maturity are deemed to be inapplicable or to provide minimal value to the assessment process.
5.5 – Flexibility
As new vulnerabilities are discovered over time and new threats to cryptography arise (e.g., quantum computers), what is assessed will inevitably change, as will the threshold of acceptability. Due to the evolving nature of acceptability, cryptography inventories will require flexibility to adapt over time in terms of what data is provided and to what level of detail.
Another consequence of acceptability is that an inventory should only be as detailed as is necessary for the anticipated set of assessments. Albert Einstein famously said, “Everything should be made as simple as possible, but not simpler.” This statement is also true of cryptography inventories. Inventories that attempt to identify all aspects of cryptography without a target for evaluation can waste time and add unnecessary complexity to the inventory-making process. Intended assessments, therefore, in part, dictate the maturity of the inventory (Section 5.4). As assessments change, the inventory graph will necessarily require updates to provide more required information.
5.6 – Contextual Usage
Another aspect that must be considered is the association of a given inventory finding in context. Information about algorithms being detected in isolation may lack contextual information that can be used to determine if cryptography is being used acceptably. For example, the inventory may detect the usage of SHA-1, but the context for this usage would be significant. Following the SHA-1 example, if the SHA-1 usage is associated with WebSockets, it may be expected and safe as defined by RFC 6455, which standardizes the WebSocket protocol. This usage of SHA-1 doesn’t depend on security properties like collision resistance; in contrast, if the usage of SHA-1 is associated with X.509 certificate thumbprint generation, there may be risks associated with its usage due to collisions [16].
Another context we must consider is using multiple entities representing different asymmetric key algorithms when used together in hybrid cryptosystems. For example, a hybrid digital signature algorithm implementation would likely use classical cryptography such as ECDSA with a quantum-resistant algorithm such as ML-DSA in such a way that both signatures must be verified; the usage of ECDSA, in this case, must not be considered as a quantum-vulnerable usage as it is used in a way that the hybrid scheme is providing robustness against the development of a CRQC as well as against a novel attack against the PQC algorithm.
6 – Conclusion
The foundation of trusted systems relies on the correct and secure application of cryptographic algorithms. Conducting a thorough cryptography inventory and assessment will identify where cryptography is in use, assess how vulnerable and critical it is to the business, and pinpoint the location of weaknesses and vulnerabilities. A CBOM offers an essential first step for creating and systematically representing this inventory, mapping cryptographic assets, entities, dependencies, and quantum security levels. Furthermore, a CBOM provides a basis for planning and effecting a transition to secure alternatives (e.g., quantum-safe algorithms). It is especially crucial for entities safeguarding data requiring prolonged (e.g., multi-decade) protection. CBOMs promise a strategic advantage, empowering organizations to effectively understand, manage, and communicate their cryptographic dependencies.
CBOMs (not unlike the SBOM concepts they enhance) are being offered now through standards-based organizations (e.g., Cyclone DX [8]). They are gaining broad adoption and maturing rapidly for use across industries. As organizations prepare for the quantum era and adhere to evolving regulatory mandates, the need for a secure and mature cryptography inventory will require further support and dialogue from the community. As organizations gear up for this transformative shift, establishing and continually refining CBOMs will be pivotal in shaping a secure and resilient future.
7 – References
| [1] | P. W. Shor, “Algorithms for quantum computation: discrete logarithms and factoring,” Proceedings 35th annual symposium on foundations of computer science, IEEE, pp. 124-134, 20 November 1994. |
| [2] | L. K. Grover, “A fast quantum mechanical algorithm for database search,” Proceedings of the twenty-eighth annual ACM symposium on Theory of computing, pp. 212-219, July 1996. |
| [3] | [Online]. Available: https://oidref.com/2.16.840.1.101.3.4.1.3. |
| [4] | [Online]. Available: https://docs.openssl.org/3.0/man3/EVP_EncryptInit. |
| [5] | [Online]. Available: https://cryptography.io/en/latest/hazmat/primitives/symmetric-encryption/#cryptography.hazmat.primitives.ciphers.Cipher . |
| [6] | “Executive Order 14028 on Improving the Nation’s Cybersecurity,” Executive Office of the President, 17 May 2021. [Online]. Available: https://www.federalregister.gov/documents/2021/05/17/2021-10460/improving-the-nations-cybersecurity. |
| [7] | “National Vulnerability Database,” [Online]. Available: https://nvd.nist.gov/. |
| [8] | “CycloneDX,” [Online]. Available: https://cyclonedx.org/. |
| [9] | “National Security Memorandum on Promoting United States Leadership in Quantum Computing While Mitigating Risks to Vulnerable Cryptographic Systems,” The White House, 4 May 2022. [Online]. Available: https://www.whitehouse.gov/briefing-room/statements-releases/2022/05/04/national-security-memorandum-on-promoting-united-states-leadership-in-quantum-computing-while-mitigating-risks-to-vulnerable-cryptographic-systems/. |
| [10] | “Memorandum for the Head of Executive Departments and Agencies on Migrating to Post-Quantum Cryptography,” Executive Office Of The President, 18 November 2022. [Online]. Available: https://www.whitehouse.gov/wp-content/uploads/2022/11/M-23-02-M-Memo-on-Migrating-to-Post-Quantum-Cryptography.pdf. |
| [11] | “Post-Quantum Cryptography,” Homeland Security, 4 October 2022. [Online]. Available: https://www.dhs.gov/quantum. |
| [12] | “Migration to Post-Quantum Cryptography: Preparation for Considering the Implementation and Adoption of Quantum Safe Cryptography,” NIST, 19 December 2023. [Online]. Available: https://csrc.nist.gov/pubs/sp/1800/38/iprd-%281%29. |
| [13] | “Post Quantum Telco Network Impact Assessment,” GSMA, 17 February 2023. [Online]. Available: https://www.gsma.com/newsroom/wp-content/uploads/PQ.1-Post-Quantum-Telco-Network-Impact-Assessment-Whitepaper-Version1.0.pdf. |
| [14] | E. Barker, W. Barker, W. Burr, W. Polk and M. Smid, “NIST Special Publication 800-57: Recommendation for Key Management”. |
| [15] | [Online]. Available: https://owasp.org/www-project-dependency-track/. |
| [16] | G. Zavercha and D. Shumow, “Are Certificate Thumbprints Unique?,” Cryptology ePrint Archive, 2019. |
| [17] | F. Yamaguchi, “Open-Sourcing the Code Property Graph Specification,” [Online]. Available: https://blog.shiftleft.io/open-sourcing-the-code-property-graph-specification-30238d66a541. |
[1] The Code Property Graph (CPG) pyramid, proposed in Open-Sourcing the Code Property Specification [17], illustrates a hierarchical view of property graphs, which is directly applicable towards the representation of CBOMs. The term “code” in a Code Property Graph is a misnomer for a true generalization of the graph, e.g., cryptography can be configured and applied in systems, over networks, and configuration files. Hence, we refer to a generalization as a “system property graph” and propose CBOMs can be represented as an application of this generalized concept.